
Selenium - это популярная библиотека с открытым исходным кодом для веб-скрапинга, которая использует протокол WebDriver для управления браузерами Chrome, Firefox и Safari. Но почему это полезно?
Традиционные инструменты для скраппинга с трудом собирают данные с веб-сайтов, которые работают на JavaScript. Это потому, что вам нужно запустить JS, а Selenium позволяет это сделать.
Библиотека также предоставляет несколько методов, позволяющих взаимодействовать со страницей так, как это делал бы пользователь, а значит, вы получаете дополнительную функциональность и более подготовлены к тому, чтобы избежать блокировки. Некоторые примеры действий:
- Прокрутка вниз.
- Нажатие на кнопки.
- Заполнение форм.
- Создание скриншотов.
Давайте разберемся в веб-скреппинге с помощью Selenium и Python!
Знакомство с Selenium
Прежде всего, мы рассмотрим шаги, необходимые для того, чтобы подготовить все необходимое для выполнения этого руководства по веб-скреппингу с помощью Selenium и запустить безголовый браузер.
Вам понадобится установленный Python 3. Поскольку во многих системах он уже настроен, возможно, вам даже не придется его устанавливать. Убедитесь в этом, выполнив приведенную ниже команду в терминале:
Терминал
python --versionЕсли у вас установлен, команда выведет что-то вроде этого:
Python 3.11.2Если возвращаемая версия 2.x или она завершается с ошибкой, вам необходимо установить Python. Загрузите Python 3.x с официального сайта и следуйте указаниям мастера установки, чтобы установить его.
Selenium поддерживает несколько браузеров, но мы будем использовать Google Chrome, поскольку он является самым популярным и занимает более 65 % рынка. Итак, вам потребуется установить:
- Google Chrome: Подойдет последняя версия браузера.
- ChromeDriver: Скачайте тот, который соответствует вашей версии Chrome.
Далее создайте новый проект на Python и установите пакет привязки Selenium:
Терминал
pip install seleniumТеперь вы готовы приступить к управлению Chrome через Selenium. Инициализируйте файл scraper.py следующим образом:
# scraper.py
from selenium import webdriver
# инициализируем экземпляр драйвера хрома (браузера)
driver = webdriver.Chrome()
# посетите целевой сайт
driver.get('https://scrapingclub.com/')
# логика скраппинга...
# освободите ресурсы, выделенные Selenium, и выключите браузер.
driver.quit()Этот Python-сниппет содержит базовую логику, необходимую для начала работы с Selenium. Он инициализирует экземпляр ChromeWebDriver и использует его для посещения ScrapingClub, целевого сайта, который мы будем использовать.
Selenium WebDriver - это инструмент автоматизации веб-процессов, позволяющий управлять веб-браузерами. Хотя он поддерживает различные браузеры, мы будем использовать Chrome.
Раньше установка WebDriver была обязательным условием, но теперь это не так. Selenium версии 4 и выше теперь включает его по умолчанию. Если у вас более ранняя версия Selenium, обновите ее, чтобы получить доступ к новейшим функциям и возможностям. Чтобы проверить текущую версию, используйте pip show selenium, а для установки последней версии используйте pip install --upgrade selenium.
Как видно, в нашем коде больше нет пути к ChromeDriver.
К вашему сведению: вы можете использовать webdriver_manager и для других браузеров. На момент написания статьи он также поддерживает GeckoDriver, IEDriver, OperaDriver и EdgeChromiumDriver.
Проверьте, что ваш Selenium-скрипт scraper.py работает, используя следующий код:
Терминал
python scraper.pyУбедитесь, что ваш скрипт Selenium scraper.py работает, используя следующий код:
Обратите внимание на сообщение ”Chrome контролируется программой автоматизированного тестирования” - это дополнительный раздел предупреждения, информирующий вас о том, что Selenium контролирует экземпляр Chrome.
Отлично! Ваш Python-скрипт работает, как и ожидалось. Но действительно ли необходимо открывать окно Chrome?
Давайте разберемся в этом.
Selenium Headless режим в Google Chrome
Selenium хорошо известен своими возможностями работы в фоновом режиме браузера (Headless). Headless browser - это браузер без графического интерфейса пользователя (GUI), но со всеми функциями настоящего браузера.Включите headless режим для Chrome в Selenium, определив соответствующий объект Options и передав его в конструктор WebDriver Chrome. Кроме того, вы должны установить headless=new, чтобы активировать безголовый режим, начиная с Chrome 109.
# scraper.py
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
# включить режим без головы в Selenium
options = Options()
options.add_argument('--headless=new')
driver = webdriver.Chrome(
options=options,
# другие свойства...
)Вот как можно включить эту функцию на предыдущих версиях браузера:
# scraper.py
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
options = Options()
# включить режим без головы
options.headless = True
driver = webdriver.Chrome(
options=options,
#...
)Теперь Selenium будет запускать экземпляр Chrome в режиме headless. Таким образом, при повторном запуске сценария вы больше не увидите окно Chrome. Это идеальная настройка для производства при запуске скрипта на сервере, так как вы не хотите тратить ресурсы на графический интерфейс.
В то же время наблюдение за тем, что происходит в окнах Chrome, полезно при тестировании скриптов, поскольку позволяет наблюдать за действием скрипта непосредственно в браузере.
Веб-скраппинг требует выбора HTML-элементов из DOM (Document Object Model) для извлечения их данных. Для этого Selenium предлагает два основных метода поиска элементов на странице:
find_element: Для поиска конкретного отдельного элемента.find_elements: Поиск всех элементов, соответствующих стратегии выбора.
Оба метода поддерживают семь различных подходов к определению местоположения элементов HTML. Вот сводная таблица:
| Поиск элемента | HTML | Selenium примеры |
|---|---|---|
By.ID | <div id="s-437">...</div> | find_element(s)(By.ID, "s-437") |
By.NAME | <input name="email" /> | find_element(s)(By.NAME, "email") |
By.XPATH | <h1>My <strong>Fantastic</strong> Blog</h1> | find_element(s)(By.XPATH, "//h1/strong") |
By.LINK_TEXT | <a href="/">Home</a> | find_element(s)(By.LINK_TEXT, "Home") |
By.TAG_NAME | <span>...</span> | find_element(s)(By.TAG_NAME, "span") |
By.CLASS_NAME | <div class="text-center">Welcome!</div> | find_element(s)(By.CLASSNAME, "text-center") |
By.CSS_SELECTOR | <div class="product-card"><span class="price"\>$140</span></div> | find_element(s)(By.CSS_SELECTOR, ".product-card .price") |
Поскольку запрос может определять более одного элемента, оба метода ведут себя следующим образом:
find_element: Возвращает первый HTML-элемент, соответствующий условию поиска.find_elements: Возвращает все элементы, соответствующие условию поиска, в виде массива.
Возможно, вы задаетесь вопросом, как определить эффективную стратегию размещения, и вот ответ: Используйте инструменты разработчика браузера на целевой странице. Для этого щелкните правой кнопкой мыши на элементе HTML и выберите ‘Inspect’, чтобы открыть DevTools:
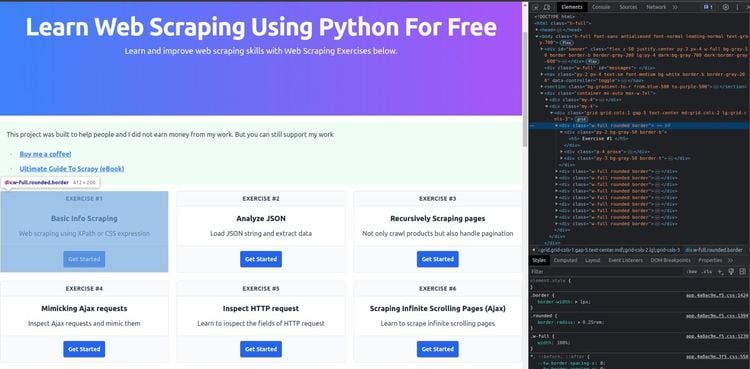
Затем проанализируйте DOM страницы и определите рабочую стратегию выбора. Вы также можете получать выражения XPath и селекторы CSS напрямую: щелкните правой кнопкой мыши на элементе, откройте меню ”Копировать” и выберите ”Копировать селектор” или ”Копировать XPath”, чтобы получить выражения, относящиеся к выбранному элементу.
Эта функция полезна при использовании подхода XPATH или CSS_SELECTOR. В то же время помните, что вы должны рассматривать эти автоматически сгенерированные селекторы только как отправную точку. Большинство из них не подходят для скраппинга, но они все же могут помочь вам понять, как работают селекторы.
Давайте посмотрим на некоторые стратегии поиска в действии! Предположим, вы хотите выбрать карточку ”Упражнение № 1”, показанную на скриншоте выше. Вы можете сделать это с помощью функции find_element():
# scraper.py
from selenium.webdriver.common.by import By
#...
exercise1_card = driver.find_element(By.CLASS_NAME, 'w-full.rounded.border')
# or
exercise1_card = driver.find_element(By.CSS_SELECTOR, '.w-full.rounded.border')
# or
exercise1_card = driver.find_element(By.XPATH, '/html/body/div[3]/div[2]/div/div[1]')Теперь, если вы хотите получить все карточки с упражнениями на странице, используйте find_elements():
# scraper.py
from selenium.webdriver.common.by import By
# ...
exercise_cards = driver.find_elements(By.CLASS_NAME, 'w-full.rounded.border')
# or
exercise_cards = driver.find_elements(By.CSS_SELECTOR, '.w-full.rounded.border')
# or
exercise_cards = driver.find_elements(By.XPATH, '/html/body/div[3]/div[2]/div/div[1]')Если вам нужно найти один HTML-элемент, вы можете выбрать By.ID. Однако не все они имеют атрибут id. Вместо этого By.CSS_SELECTOR и By.XPath позволяют выбрать любой HTML-элемент в DOM. Поэтому рекомендуется использовать селекторы CSS или выражения XPath. find_element() и find_elements() возвращают один или много объектов Selenium WebElement, соответственно. Но что такое WebElement в Selenium и что вы можете с ним делать?
Когда пользователи посещают веб-страницу в браузере, они взаимодействуют с ней через ее HTML-элементы: нажимают на них, читают их данные, используют для ввода информации и т. д. Это лишь некоторые действия, которые можно выполнять на странице с помощью ее элементов.
Объект Selenium WebElement представляет собой узел HTML в DOM, а WebElement раскрывает несколько методов для взаимодействия с базовым элементом.Это позволяет вам играть с узлами DOM так, как это делал бы пользователь.
Давайте посмотрим пример! Подключитесь к странице формы входа в систему ScrapeClub в Selenium. Вот как выглядит форма входа в систему:
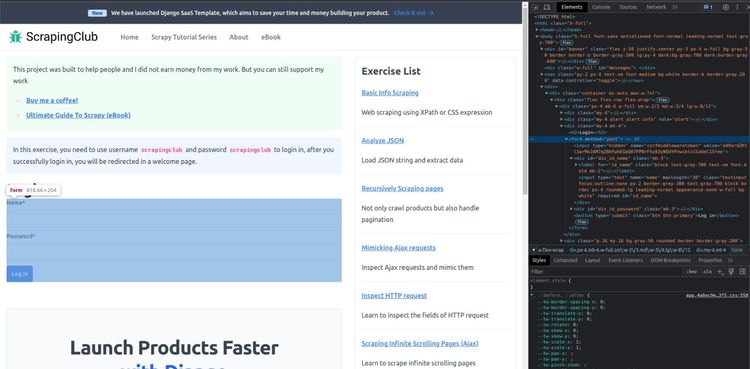
Некоторые из наиболее распространенных действий, которые можно выполнять с объектами WebElement, следующие:
- Клик по HTML-элементу
# scraper.py
submit_button = driver.find_element(By.CSS_SELECTOR, 'form button')
submit_button.click()Этот фрагмент нажимает на кнопку ”Войти” и отправляет форму. Метод click() позволяет щелкнуть по выбранному элементу.
- Ввод данных в текстовый элемент HTML:
# scraper.py
name_input = driver.find_element(By.ID, 'id_name')
name_input.send_keys('Serena')Этот код заполняет элемент ввода ”Name” значением ”Serena”. Метод send_keys() WebElement имитирует ввод текста.
- Получение текста, содержащегося в элементе HTML:
# scraper.py
name_label = driver.find_element(By.CSS_SELECTOR, 'label[for=id_name]')
print(name_label.text)- Получение данных, содержащихся в атрибутах элемента HTML:
# scraper.py
hidden_input = driver.find_element(By.CSS_SELECTOR, 'input[type=hidden]')
hidden_input_value = hidden_input.get_attribute('value')
print(hidden_input_value)Последние два примера особенно полезны, когда речь идет о веб-скрапинге в Python Selenium. Не забывайте, что вы также можете вызвать find_element() и find_elements() для WebElement. Это ограничит поиск дочерними элементами выбранного HTML-элемента.
Ожидание появления элемента
Большинство сайтов полагаются на вызовы API для получения необходимых данных.После первой загрузки они выполняют множество асинхронных XHR-запросов через AJAX на JavaScript.Таким образом, они получают некоторый контент, а затем используют его для заполнения DOM на лету новыми HTML-элементами. Именно так работают популярные технологии рендеринга на стороне клиента, такие как React, Vue и Angular.
Когда вы осматриваете веб-страницу, есть вероятность, что с момента первой загрузки прошло некоторое время, поэтому она уже должна была выполнить самые важные API-запросы, а DOM страницы, скорее всего, окончательно заполнен.
Посмотрите на вкладку ”Сеть” в окне DevTools. В разделе ”Fetch/XHR” вы можете увидеть AJAX-запросы, выполненные страницей:
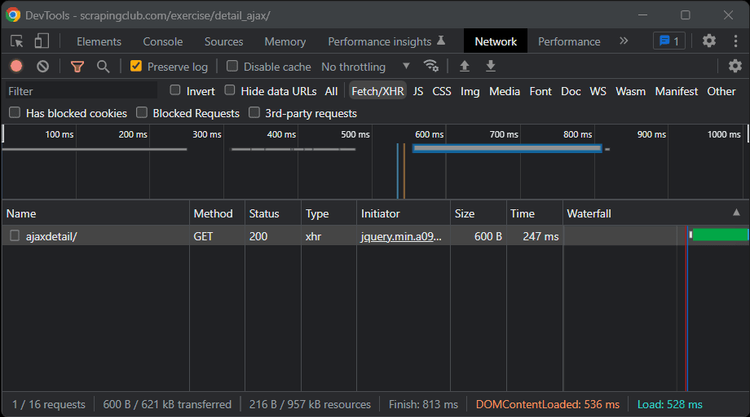
Сравните исходный код HTML с текущим DOM, чтобы изучить различия.Используйте инструменты разработчика, чтобы понять, что делает целевая страница и как она использует JavaScript для манипулирования DOM. Помните, что веб-сайт может полагаться на JavaScript для полного рендеринга своих страниц или только их части.
На страницах с JS-рендерингом нельзя сразу же приступать к сбору данных. Это связано с тем, что DOM будет завершен только через некоторое время. Другими словами, вам придется подождать, пока JavaScript сделает свою работу.
У вас есть два способа соскрести данные с таких страниц с помощью Selenium:
time.sleep() останавливает скрипт Python и Selenium на несколько секунд, прежде чем выбрать элементы из DOM. WebDriverWait ожидает определенных условий, прежде чем продолжить работу с кодом. Использование функции time.sleep() в Python работает в большинстве случаев. Но как долго вы должны ждать? Абсолютного ответа нет, поскольку все зависит от конкретного случая и условий сети. Но точно можно сказать, что слишком долгое или слишком малое ожидание не является идеальным в любом случае.
Именно поэтому вам следует предпочесть второй подход, основанный на классе Selenium ёWebDriverWaitё. Это позволит вам ждать только столько, сколько необходимо.
# scraper.py
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
# ...
# wait up to 3 seconds until there is the 'Jersey Dress' string
# in the '.card-title' element
element = WebDriverWait(driver, 3).until(
EC.text_to_be_present_in_element((By.CSS_SELECTOR, '.card-title'), 'Jersey Dress')
)
# you are now sure that the card has been loaded
# and can scrape data from it
product_name = driver.find_element(By.CSS_SELECTOR, '.card-title').text
product_image = driver.find_element(By.CSS_SELECTOR, '.card-img-top').get_attribute('src')
product_price = driver.find_element(By.CSS_SELECTOR, '.card-price').text
product_description = driver.find_element(By.CSS_SELECTOR, '.card-description').text
print(f'Product title: {product_name}')
print(f'Product image: {product_image}')
print(f'Product price: {product_price}')
print(f'Product description: {product_description}')Этот код ждет до трех секунд, пока HTML-элемент заголовка карточки не будет содержать ожидаемый текст. Как только условие выполнено, он извлекает данные из карточки. Однако если ожидаемое условие не наступает в течение указанного таймаута, возникает исключение TimeoutException.
Бесконечная прокрутка
При бесконечной прокрутке - эффективном подходе, используемом веб-сайтами, чтобы избежать пагинации и, следовательно, избавить пользователей от необходимости нажимать кнопку мыши для загрузки следующих страниц - новый контент загружается динамически через AJAX по мере прокрутки пользователем страницы вниз.
Чтобы соскрести страницу, использующую бесконечную прокрутку для загрузки данных, нужно дать браузеру команду прокрутить страницу вниз. Как? С помощью пробела, клавиш ”Page Down” или ”End”.
Чтобы имитировать нажатие клавиши “End” на веб-странице, сначала нужно выбрать элемент (например, <body>) и отправить туда клавишу:
# scraper.py
from selenium.webdriver import Keys
# ...
driver.find_element(By.TAG_NAME, 'body').send_keys(Keys.END)Когда речь идет о бесконечной прокрутке, вам придется применять эту логику несколько раз, пока загрузятся все элементы. Кроме того, необходимо дождаться появления нового элемента, как объяснялось ранее. Этого можно добиться в Selenium с помощью Python, как показано ниже:
# scraper.py
cards = []
old_card_size = len(cards)
while True:
# reach the end of the scroll bar
driver.find_element(By.TAG_NAME, 'body').send_keys(Keys.END)
# wait 3 seconds for new elements to load
time.sleep(3)
# retrieve all cards
cards = driver.find_elements(By.CSS_SELECTOR, '.w-full.rounded.border')
# if no new cards were found
if (old_card_size == len(cards)):
# break the cycle since the scroll
# is over
break
# keep track of the number of cards
# currently discovered
old_card_size = len(cards)
# scrape data from cards...Этот цикл while позволяет соскрести всю информацию из появляющегося контента. Однако следует помнить, что вы не можете заранее знать, какие элементы будут загружены, а значит, не знаете, какое условие ожидать в WebDriverWait. Поэтому в данном случае лучше выбрать time.sleep().
Заполнение формы
Вот как вы можете использовать Selenium для заполнения формы на странице с формой входа в ScrapingClub:
# scraper.py
# retrieve the form elements
name_input = driver.find_element(By.ID, 'id_name')
password_input = driver.find_element(By.ID, 'id_password')
submit_button = driver.find_element(By.CSS_SELECTOR, 'form button[type=submit]')
# filling out the form elements
name_input.send_keys('scrapingclub')
password_input.send_keys('scrapingclub')
# submit the form and log in
submit_button.click()Делаем скриншот с помощью Selenium
Помимо соскабливания (scraping/скрейпинг) текстовых данных, Selenium позволяет делать скриншоты - функция, полезная для отладки, подкрепления диссертации визуальными доказательствами или просмотра вариантов пользовательского интерфейса. Например, вы можете сделать скриншоты, чтобы проверить, как конкуренты представляют продукты на своих сайтах.
# scraper.py
driver.save_screenshot('screenshot.png')